

MLOps: What it is and why does it Matter?
Machine Learning Operations is a process of automating and productionalizing machine learning applications and workflows.
I help companies to leverage Machine Learning to create innovative products through an end-to-end machine learning development process that designs, builds, and manages reproducible, testable, scalable, and evolvable ML-powered software with minimal cost.
"The real problem with a Machine learning system will be found while you are continuously operating it for the long term." Google.
I start this post with the above quote from Google. Machine learning systems are awesome. They have been applied to a variety of problems and have increased the value of solutions in areas such as healthcare, finance, marketing, retail, manufacturing, etc. More and more companies are developing Machine Learning (ML) models to help their businesses grow. But many are still struggling to bridge the gap to practical deployments.
Despite ML is maturing from research to applied business solutions, many companies haven't figured out how to realize their AI ambitions, according to a report by Algorithmia. Bridging the gap between ML model building and practical deployments is still a challenging task. Although AI investments are on the rise, only 13% of companies using machine learning have successfully deployed a model, that's, just one out of every 10 as presented by Deborah Leff (CTO for Data Science and AI at IBM) and Chris Chap (Senior Vice President of Data and Analytics at Gap).
Rackspace presented a survey in January of 2021 saying that 80% of companies are still exploring or struggling to deploy ML models.
Why is it so hard to convert the data sciences discoveries into tangible value for the business?
How can companies evolve from managing just one model to managing tens, hundreds, or even thousands?
What kind of practices and professionals do organizations need?
In this blog post, I'll try to answer those questions and explain why you should invest in a systematic approach to operationalizing AI using Machine Learning Operations (MLOps).
The typical ML workflow
First, let's see how is a typical ML workflow. You start defining your prediction task, that is, what problem you want to solve. Then, you need to collect the data (data ingestion), and analyze and transform it (pre-processing). Once you have the data cleaned you then create and train your model, evaluate it, and optimize it. Finally, you deploy it to make predictions.
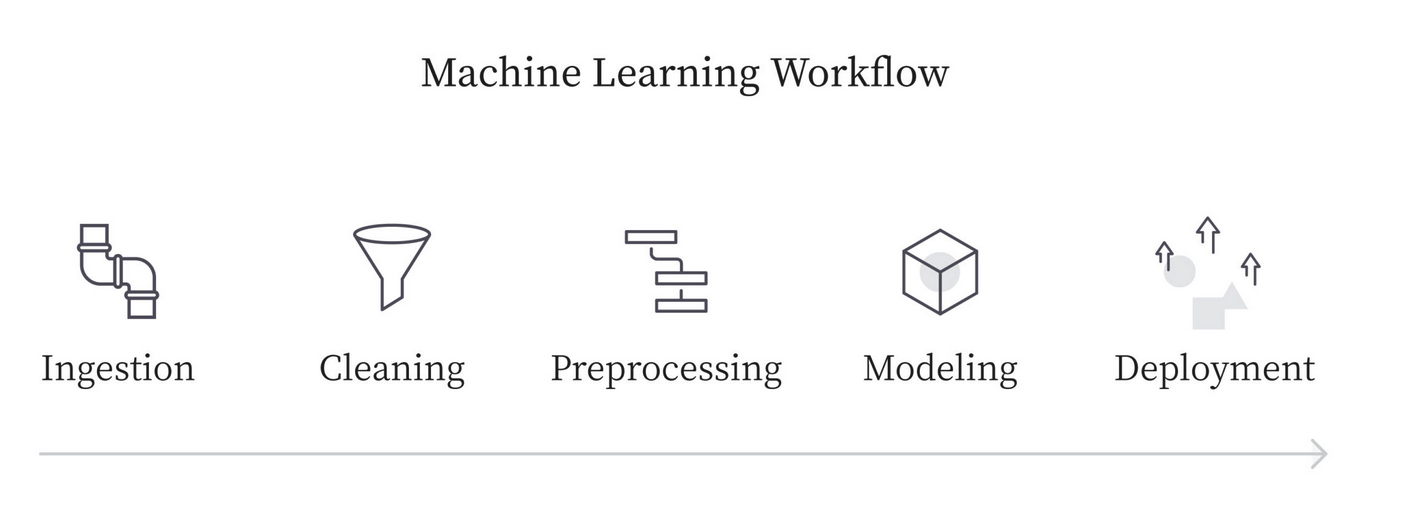 Fig. 1: The typical ML workflow.
Fig. 1: The typical ML workflow.
We often talk about the deployment of machine learning models when, in fact, we mean the deployment of a machine learning pipeline.
What is a machine learning pipeline?
A pipeline is a way of modeling workflows as a set of connected steps. Each step takes as input the output of the previous step and performs some additional computations, and produces outputs that can be utilized by the future components. In other words, It is the series of steps that need to occur from the moment we received the data up to the moment we obtain a prediction.
A typical machine learning pipeline includes a big proportion of feature transformation steps. Then it includes steps to train the machine learning model and steps to output a prediction. But once you deploy it on production, you may ask yourself: how can I make sure my ML pipeline will run smoothly in production all the time?
As the ML community continues to accumulate years of experience with live systems, a widespread and uncomfortable trend has emerged: developing and deploying ML systems is relatively fast and cheap, but maintaining them over time is difficult and expensive. Deploy an ML model in production is only the first iteration, in the paper Hidden Technical Debt in Machine Learning Systems (NIPS’15) the authors shown that ML systems have a special capacity for incurring technical debt because they have all of the maintenance problems of traditional code plus an additional set of ML-specific issues. This debt may be difficult to detect because it exists at the system level rather than the code level. Traditional abstractions and boundaries may be subtly corrupted or invalidated by the fact that data influences ML system behavior. Typical methods for paying down code-level technical debt are not sufficient to address ML-specific technical debt at the system level. These risks scale depending on the impact the ML systems have on the organization and the probability of one of these risk events occurring.
The machine learning code is typically a small part of an overall solution, a deployment pipeline may also incorporate the additional steps required to package your model for consumption as an API by other applications and systems.
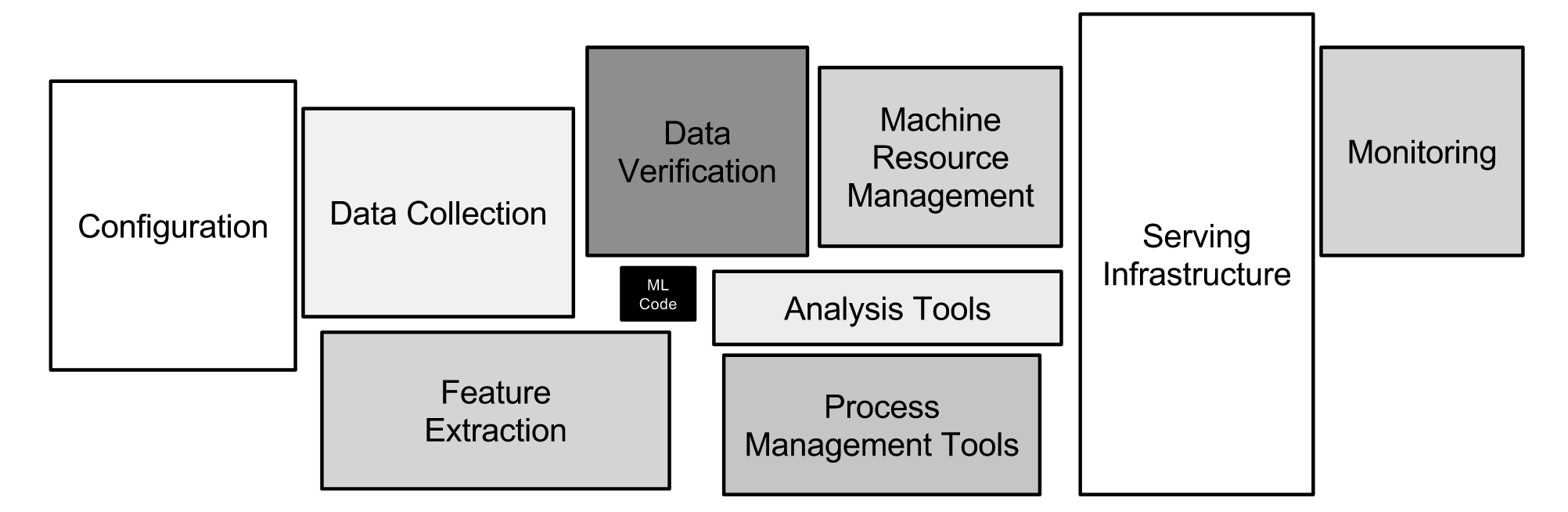 Fig 2. Only a small fraction of real-world ML systems are composed of the ML code, as shown by the small black box in the middle. The required surrounding infrastructure is vast and complex. Source: Google.
Fig 2. Only a small fraction of real-world ML systems are composed of the ML code, as shown by the small black box in the middle. The required surrounding infrastructure is vast and complex. Source: Google.
Here are two really good papers that explore this issue:
- Machine Learning: The High-Interest Credit Card of Technical Debt NIPS’14
- What’s your ML test score? NIPS’16
These papers categorize and present several machine learning anti-patterns that can lead you to a failure in your ML project in the long term.
As organizations are deploying more and more models in production each day, managing all these ML workflows and pipelines can become a nightmare. Machine Learning Operations (MLOps) rises to mitigate the risks of technical debts in ML systems.
Google defines MLOps as a software engineering culture and practice that aims at unifying ML system development and ML system operations. It strongly advocates automation and monitoring at all steps of ML system construction, from integration, testing, and releasing to deployment and infrastructure management.
MLOps is a way of standardizing and streamlining a machine learning project’s lifecycle management. It allows organizations to alleviate many of the issues on the path to AI with ROI by providing a technological backbone for managing the machine learning lifecycle through automation and scalability. MLOps try to make the development, deployment, and monitoring of machine learning systems more systematic, repeatable, and reliable.
Dataiku published a book, where they discuss three key factors why MLOps is becoming so important to organizations:
ML projects have many dependencies, like data. But not only is data constantly changing but also business needs shift as well. ML and business metrics need to be continually monitored to ensure that the reality of the model in production meets the original goal.
The historical data used to train models changes over time, this can lead to data drift or concept drift. The first one (data drift) happens when the distribution of the input variables in production is meaningfully different from the ones used in training. As a result, the trained model is not relevant for this new/production data. The second one (concept drift) occurs when the patterns the model learned no longer hold, that is, the very meaning of what we are trying to predict evolves (labels changes). Depending on the scale, this will make the model less accurate or even obsolete. So, data is a reflection of real-world behaviors and processes, and these use to change over time. This was especially clear with the onset of Covid-19, where lockdowns forced completely different behaviors onto consumers and many retail analytics models broke in production. Thus, ML models must continuously adapt to these changes so that the ML system keeps solving the original problem it intended to solve.
Organizations lack data literacy, that is, not everyone speaks the same language. Common data team members (data scientists, subject matter experts, data engineers, etc.) often speak a very different technical language than product owners and software engineers, compounding the usual problem of translating business requirements into technical requirements.
Data scientists are not software engineers. They don’t have engineering skills or experience in building applications, so they are facing a trade-off between developing and iterating on models and maintaining them in production. The complexity increases considering the turnover of staff on data teams and, suddenly, data scientists have to manage models they did not create.
Thus, creating a new tool/service/app/product that has AI in the core is not just a technology initiative; it's a people initiative. The design process forces us to empathize with people, and it necessarily includes all the people: internal stakeholders and players, as well as the end-users/customers of the service.
Research ML Vs Production ML

The deployment of a machine learning model is the process of making our model available in production environments where it can provide predictions to other software systems.
The development process of an ML model is done in a so-called research environment. This is an isolated environment without contact to live data when the data scientist has the freedom to try and research the different models and find out a solution to a certain product need.
In a common setting, we have historical data and we use this data to train a machine learning model. Once we're happy with the performance of our model in the research environment, we're ready to migrate it to the production environment where it can receive input from live data and output predictions that can be used to make decisions.
The challenges when doing production ML are very different than academic or research ML, or in some sense, they're the same but include a lot more. There’s a huge difference between building a Jupyter notebook model in the lab and deploying a production system that generates business value.
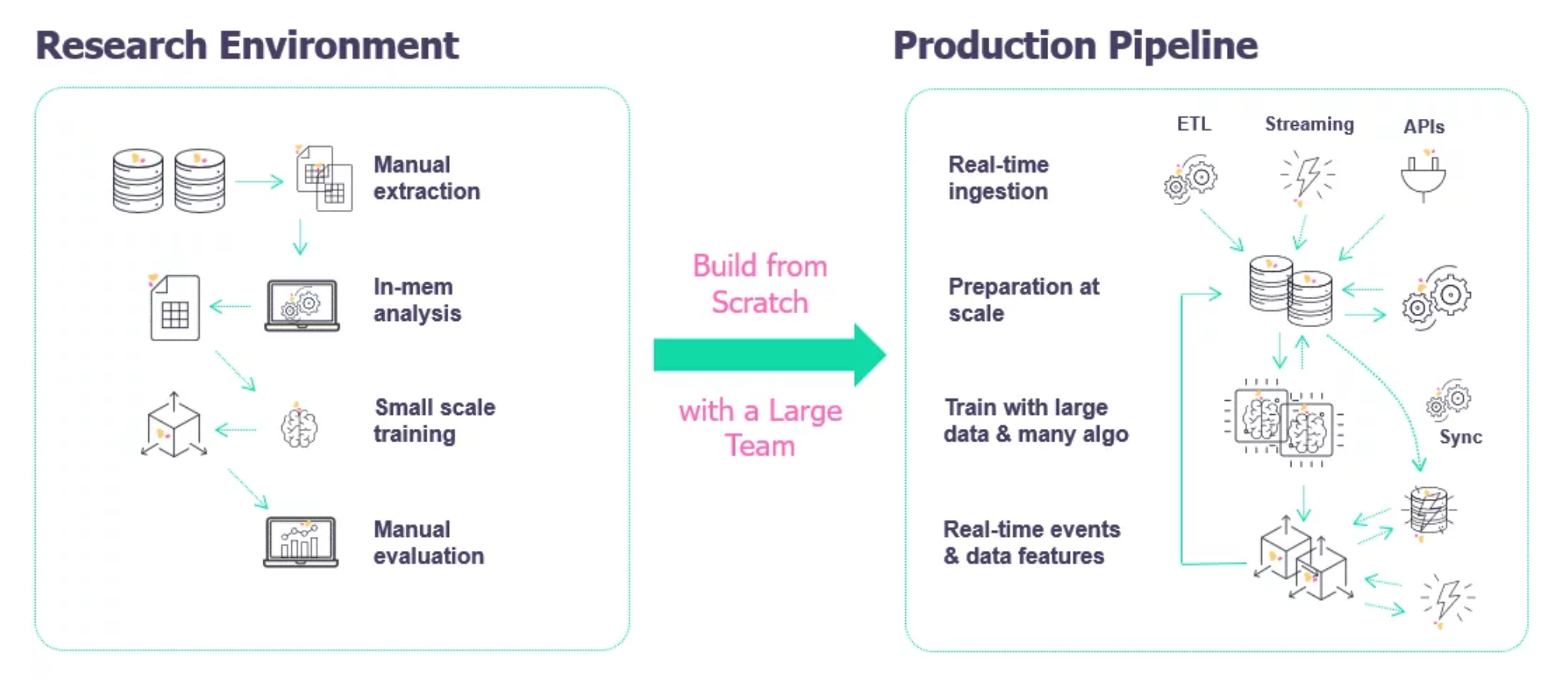 Fig 3. Image source: iguazio.com.
Fig 3. Image source: iguazio.com.
In an Academic/Research ML environment you work with historical (static) data focusing on achieving the highest overall accuracy. The training and tuning process can take days and fairness is important but not critical. On the other hand, in a Production ML environment, you have to deal with dynamic-shifting data, and need to create a model ready to fast inference and good interpretability. Also, you need to continuously assess and retrain your model to handle changes in your input data (data drift, concept drift, etc.). Finally, in a production environment, fairness is crucial and the challenge is not only to achieve high accuracy but to build the entire ML system where you need to think about operating it continuously in production, and for online use cases, that means it has to stay available 24/7 and try to do all of this at the minimum cost while producing the maximum performance.
Software Development VS ML development
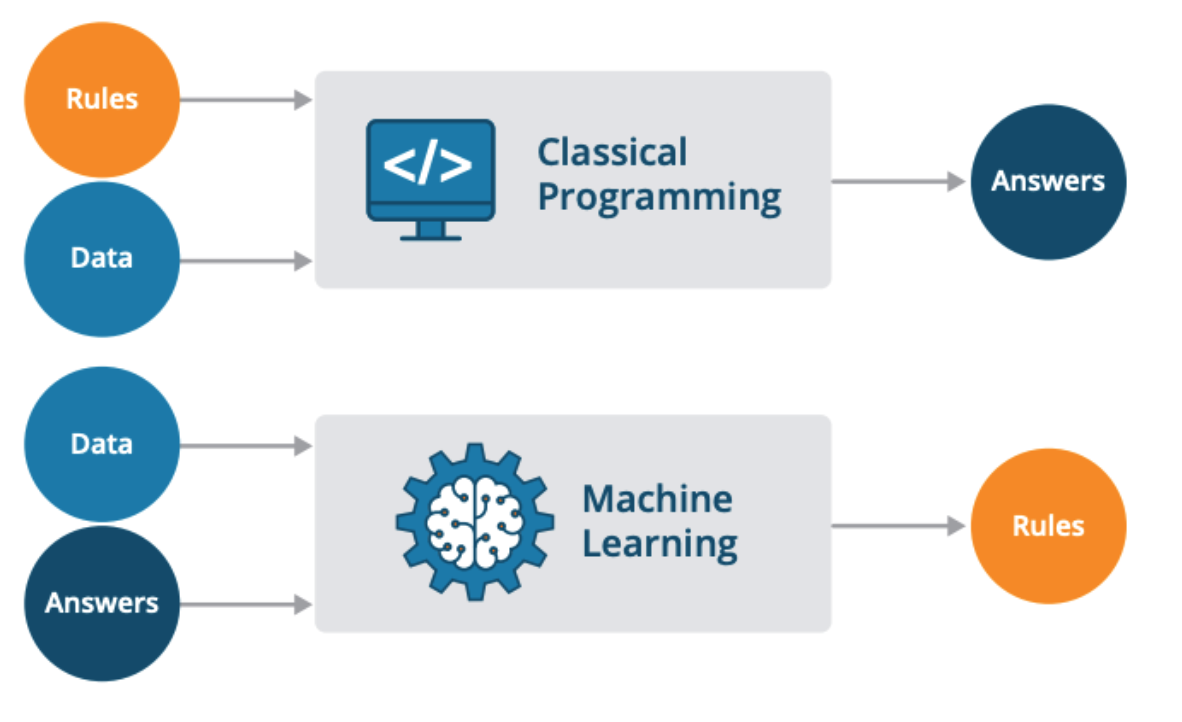 Fig 4. Source: Twimlai
Fig 4. Source: Twimlai
In addition to the “traditional” software engineering problems, machine learning systems also face new challenges. In contrast with typical software systems, with are traditionally code-centric, ML systems involved an intricate relationship between data code and model. ML is not just code, it is code plus data that creates a model. Thus, code, data, and models are unique artifacts with their own dependencies and pitfalls. The joint management of these artifacts is a challenge in delivering and maintaining production ML systems.
As many applications are becoming AI-centric, software development is evolving to facilitate ML. MLOps will play a key role in the management of code, data, and model changes over time.
MLOps vs DevOps
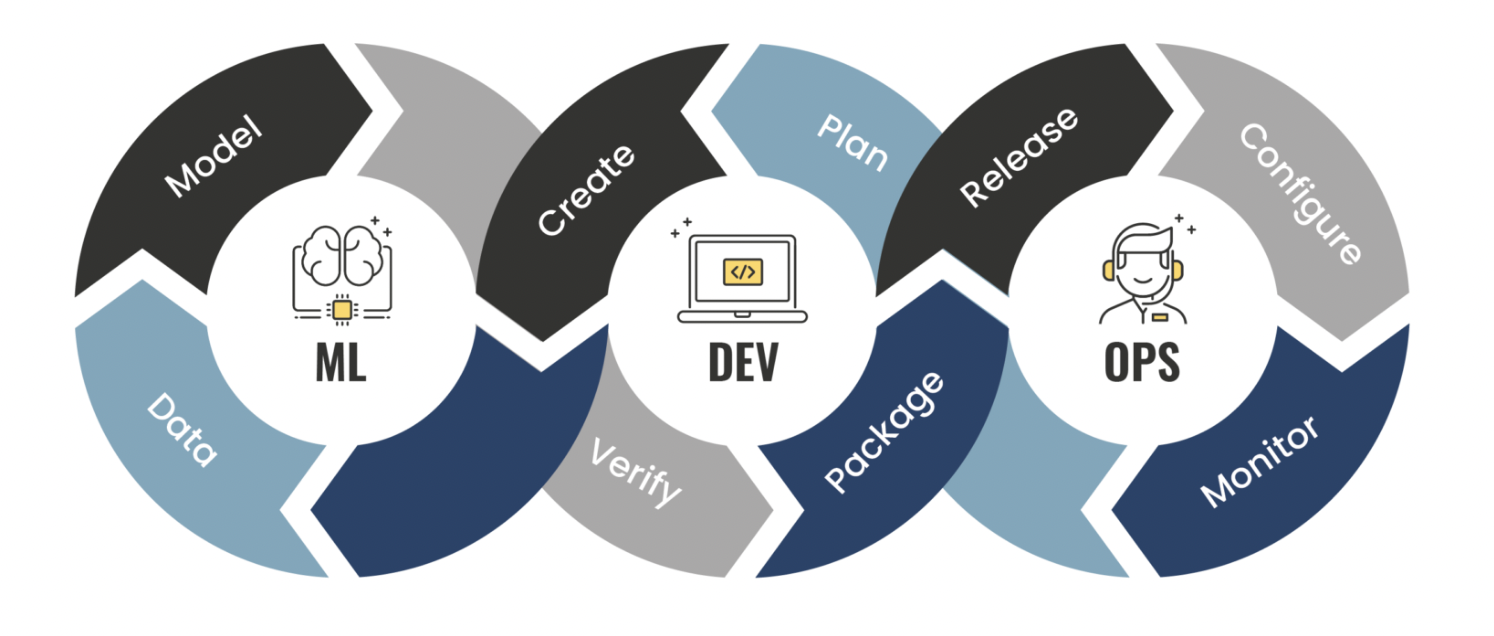 Fig 5. Source: phdata
Fig 5. Source: phdata
The DevOps method extends agile development practices by further streamlining the movement of software change through the build, test, deploy, and delivery stages. DevOps empowers cross-functional teams with the autonomy to execute their software application driven by continuous integration, continuous deployment, and continuous delivery. It encourages collaboration, integration, and automation among software developers and IT operators to improve the efficiency, speed, and quality of delivering customer-centric software.
The MLOps and DevOps have a lot in common. For example, they both center around:
- Robust automation and trust between teams.
- The idea of collaboration increased communication between teams.
- The end-to-end service life cycle (build, test, release).
- Prioritizing continuous delivery and high quality.
However, MLOps differs from DevOps in the same areas where machine learning development differs from traditional software development. The MLOps pipeline incorporates additional data and model steps that are required to build/train a machine learning model. MLOps focuses on the intersection of data science and data engineering in combination with existing DevOps practices to streamline model delivery across the machine learning development lifecycle.
DevOps projects use Infrastructure-as-Code (IaC) and Configuration-as-Code (CaC) to build environments, and pipelines-as-code to ensure consistent and reliable CI/CD patterns. In MLOps, the pipelines have to integrate with Big Data and ML training workflows. That often means that our pipeline is a combination of a traditional CI/CD tool and new workflow engines.
In ML data becomes part of your system and defines your output, thus:
- Continuous integration is not only about testing your code, but also validating your data and its quality;
- Automated testing must include proper validation of the data and ML model;
- Continuous delivery is no longer a single package, but a pipeline that brings forth a prediction service;
- Pipelines must also version input data, code, and the ML models to provide for reproducibility and traceability.
- As data changes constantly, resulting in decay of the model's performance, models need to be monitored and alerts need to be created to enable Continuous Training to automatically retrain models.
MLOps is an emerging set of practices that fuses ML with software development by integrating multiple domains like ML, DevOps, and data engineering which aims to build, deploy and maintain ML systems in production reliably and efficiently.
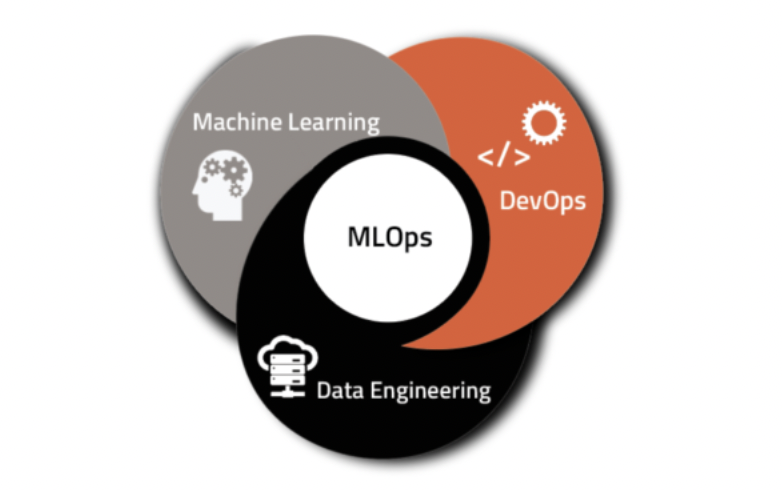 Fig. 6: MLOps intersection. Designed by UbiOps
Fig. 6: MLOps intersection. Designed by UbiOps
MLOps is a culture that aims to unify ML system development and operations and guide to the challenges of taking ML projects from experiments to production while managing the lifecycle of data, models, and code.
MLOps Practices
Pushing ML models into production without MLOps infrastructure is a risk for many reasons, but first and foremost because fully assessing the performance of an ML model can often only be done in the production environment. Why? Because prediction models are only as good as the data they are trained on, which means the training data must be a good reflection of the data encountered in the production environment. If the production environment changes, then the model performance is likely to decrease rapidly. Thus, MLOps is quickly becoming a critical component of successful data science project development in the enterprise.
Hybrid Teams
From the several risks described above, it's clear that the Data Scientist alone cannot create ML products. To reduce ML technical debts you need a set of skills from a hybrid team that, together, covers all areas of MLOps. In the most likely scenario, right now, your team would include a Subject Matter Expert, a Data Scientist or ML Engineer, a DevOps Engineer, and a Data Engineer.
Build reproducible ML Pipelines
Data teams that cannot access high-quality and relevant data or work in the correct collaborative environment are not able to succeed in AI projects, regardless of their competence. Thus, when we create our ML pipeline, we need to do it in a way so that the pipelines/experiments are reproducible. Imagine the time lost because we need to spend a lot of time trying to figure out why two models have different results.
In order to have reproducibility, consistent version tracking is essential. In typical software development, versioning code is enough, because all behavior is defined by it. In ML, we also need to track model versions, along with the data used to train it, and some meta-information like training hyperparameters.
Thus, with experiment tracking you log/track all metrics, code, hyperparameters, and data used in your experiments so you can look back to determine what combination of attributes, parameters, and data transformations leads to better performance. Experiment tracking helps data scientists work more effectively and gives us a reproducible snapshot of their work.
Automated Data Validation
In computer science, garbage in, garbage out is the concept that flawed, or nonsense input data produces nonsense output. It is commonly used to enforce the need for quality data to train your ML models. A good data pipeline usually starts by validating the input data.
Common validations include:
- File format and size;
- Column types for structured data;
- Null or empty values and invalid values
- Check and save the statistical properties of the data (average, variance, max, min values, etc.);
Data validation is an essential part of any data handling task. While data validation is a critical step in any data workflow, like an ML pipeline, it’s often skipped over. It may seem as if data validation is a step that slows down your pace of work, however, it is essential because it will help you create the best results possible and reduce the chances of your getting a biased or inaccurate model.
Automated Model Validation
A common practice in DevOps is test automation, where the software needs to pass through unit tests, integration tests, and others before the deployment of a new version. This reduces the risks of bugs and other issues in production.
Before deploying the model you need to validate it both technically and from a business standpoint. This validation usually includes a staged deployment process in a QA phase where all required validation can happen in a low-cost test environment (model fairness and most important features). Model behavior needs to be analyzed in-depth as biased input data produces biased results, an increasing concern for business stakeholders. Thus, the validation of model behavior is essential for responsible AI practices to ensure that models that are created follow ethical standards.
Creating automated tests for ML is a tough task because no model gives 100% correct results. This means that model validation tests need to be necessarily statistical in nature, rather than having just pass/fail status. In order to decide whether a model is good enough for deployment, one needs to decide on the right set of metrics to track and the thresholds of their acceptable values, usually empirically, and often by comparison with previous models or benchmarks. Having a well-chosen set of automated tests can give confidence to the data team, accelerating the deployment speed, consistency, and reliability.
Model Monitoring
Pushing models into production is not the final step of the ML life cycle, is actually far from it. It's often just the beginning of monitoring its performance and ensuring that it behaves as expected. Thus, the next step is to monitor the model performance in production. This monitoring not only happens from a technical metrics perspective, like performance, software errors, and latency to server predictions but also to monitor input data quality to detect data or concept drifts. AI systems may be affected by factors that we have much less control over. Thus, the monitoring system must also capture the quality of model output, as evaluated by a set of appropriate ML and business metrics.
In the same way, as we validate data and models we need to monitor metrics across slices or groups of data, and not just globally, to be able to detect problems affecting specific segments, like different prediction patterns for males and females.
Thus, a good monitoring process ensures (at defined periods - daily, monthly, etc.) that model performance is not degrading in production. Monitoring of the pipeline should be accessible to the Data Science team and the IT department, as both have a role to play in maintaining a healthy system.
Infrastructure and environment Automation
An indicator of excellent MLOps infrastructure is whether it makes complex (cloud) infrastructure abstract so that even people without much knowledge of the infrastructure can easily train and deploy models. By creating standardized processes data scientists will no longer need to focus energy on setting up code environments, structuring experiments, or other routine tasks that do not align with their areas of expertise. MLOps can maximize the productivity of your team dramatically and allocate more time for the relevant tasks generating more value for your business.
Governance
To responsibly deploy AI systems, models must be trained on compliant and unbiased data sources, have interpretable and explainable results, and accountability throughout the organization where it is easy to find where in the development pipeline something potentially went wrong to fix it effectively.
With decision automation (decision making without human intervention) models become more critical, and, in parallel, managing model risks become more important at the top level. The reality of the ML life cycle in an enterprise setting is much more complex.
Thus, responsible AI It's a process that helps organizations and business leaders generate long-term value and reduce the risks associated with data science, machine learning, and AI initiatives. These are not optional practices. They are essential tasks for not only efficiently scaling data science and ML at the enterprise level but also doing it in a way that doesn't put the business at risk. Teams that attempt to deploy data science without proper MLOps practices in place will face issues with model quality and continuity -- or worse, they will introduce models that have a real, negative impact on the business (e.g., model that makes biased predictions that reflect poorly on the company).
Final Thoughts
I see MLOps as a set of practices that combine Machine Learning, DevOps, and Data Engineering, which aims to deploy and maintain ML systems in production reliably and efficiently. It improves the lifecycle management of Machine Learning solutions enabling better automation, replicability, resiliency, monitoring, and scalability.
As ML matures from research to applied business solutions, we need to improve the efficiency and efficacy of its operational processes. At the core, MLOps is a process that enables data scientists and IT or engineering teams to collaborate and increase the pace of model development alongside continuous integration and deployment with proper monitoring and validation, and governance of the ML models.
Organizations that adopt MLOps practices are more likely to be successful in their implementations of ML, project management, CI/CD, and quality assurance, helping customers improve delivery time, reduce defects, and make data scientists more productive.
This is a brand new area in the AI field, with tools and practices that are likely to keep evolving and maturing fast. There are a lot of open-source and enterprise solutions that handle one or more of the practices described here.
I hope you may find this post useful. Stay tuned for new posts about MLOps, detailed examples, and tutorials on how to apply MLOps practices in your organization.
MLOps resources
Open-Source solutions
- https://dstack.ai/
- https://github.com/allegroai/clearml
- https://github.com/mlrun/mlrun
- https://github.com/datarevenue-berlin/OpenMLOps
- https://www.kubeflow.org/
- https://www.tensorflow.org/tfx/
- https://mlflow.org/
- https://www.acumos.org/
Enterprise Solutions
- https://www.datarobot.com/platform/mlops
- https://algorithmia.com/mlops
- https://cloud.google.com/vertex-ai
- https://aws.amazon.com/pt/sagemaker/mlops/
- https://cnvrg.io
- https://valohai.com
Where can you learn
- https://madewithml.com/
- https://mlops.org
- https://github.com/kelvins/awesome-mlops
- https://github.com/visenger/awesome-mlops
- https://github.com/aniruddhachoudhury/awesome-mlops-1
References
- Engineering MLOps: Rapidly build, test, and manage production-ready machine learning life cycles at scale. Emmanuel Raj.
- https://www.coursera.org/specializations/machine-learning-engineering-for-production-mlops
- https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/
- https://blog.deeplearning.ai/blog/the-batch-companies-slipping-on-ai-goals-self-training-for-better-vision-muppets-and-models-china-vs-us-only-the-best-examples-proliferating-patents
- https://www.udemy.com/course/deployment-of-machine-learning-models
- https://www.datacamp.com/community/blog/the-past-present-and-future-of-mlops
- https://abhijit-digital.medium.com/mlops-101-a1c7dd9f9807
- https://www.phdata.io/blog/mlops-vs-devops-whats-the-difference/
- https://www.phdata.io/blog/what-is-mlops-and-why-do-i-need-it/
- https://towardsdatascience.com/ml-ops-machine-learning-as-an-engineering-discipline-b86ca4874a3f



