Data Analysis of used cars on eBay
This project presents an exploratory data analysis of a used cars from eBay.

I help companies to leverage Machine Learning to create innovative products through an end-to-end machine learning development process that designs, builds, and manages reproducible, testable, scalable, and evolvable ML-powered software with minimal cost.
This project presents an exploratory data analysis of a database provided by Kaggle.
The dataset contains over 370,000 used cars scraped from eBay Kleinanzeigen.
The dataset is available on GitHub or can be downloaded from https://www.kaggle.com/orgesleka/used-cars-database
The analysis was drive by several questions, that were answered through tables or graphs.
Problem
Answers questions about cars sold on eBay Kleinanzeigen.
Questions:
- What is the distribution of vehicles by the year of registration?
- What is the Variation of the price range by type of vehicle?
- What is the number of vehicles for selling by type of vehicle?
- How many vehicles belong to each brand?
- What is the average vehicle price based on the type of vehicle and the type of gearbox?
- What is the average vehicle price based on the type of fuel and the type of gearbox?
- What is the average power of a vehicle by type of vehicle and type of gearbox?
- What is the average price of a vehicle by brand and type of vehicle?
Solution
Perform an Exploratory Data Analysis (EDA) to answer the above questions.
Results
All the questions were answered from the EDA using Python, Pandas, Matplotlib, and Seaborn.
Source code
The solution is also available at Github.

How to use
- You will need Python 3.5+ to run the code.
- Python can be downloaded here.
- You have to install some Python packages, in command prompt/Terminal:
pip install jupyter-lab numpy pandas seaborn matplotlib Once you have installed the required packages, just clone/download this project:
git clone https://github.com/cpatrickalves/eda-ebay-cars.gitAccess the project folder in command prompt/Terminal and run the following command:
jupyter-labThen open the data-analysis.ipynb file.
Data Analysis of used cars from eBay Kleinanzeigen
Above the EDA is presented with the source code used to perform the data pre-processing, data transformation, and image generation.
# Imports
import os
import subprocess
import stat
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datetime import datetime
sns.set(style="white")
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
Data Preparation
First, let's load the database and see how it looks.
# Loading the dataset
dataset = pd.read_csv('dataset/autos.csv', encoding='latin-1')
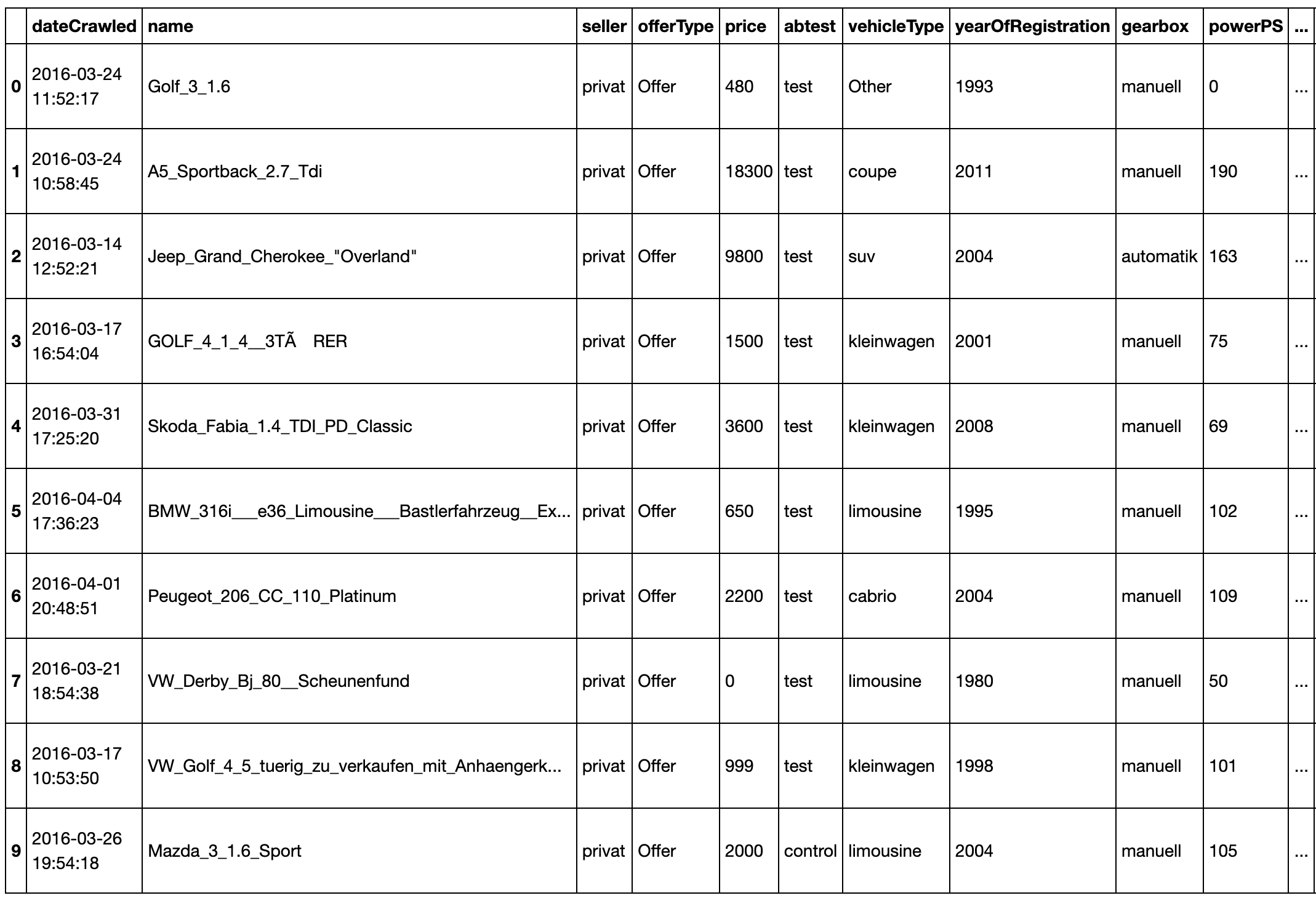
# Print the first 10 rows
dataset.head(10)
# Print the size of dataset
print('Number of columns: {}'.format(dataset.shape[1]))
print('Number of rows: {}'.format(dataset.shape[0]))
Number of columns: 27
Number of rows: 313687
So, the database has 27 columns and 313,687 rows. Let's check each one of the columns and the data types.
# Column names and data type (string, int, float, etc.)
dataset.dtypes
dateCrawled object
name object
seller object
offerType object
price int64
abtest object
vehicleType object
yearOfRegistration int64
gearbox object
powerPS int64
model object
kilometer int64
monthOfRegistration object
fuelType object
brand object
notRepairedDamage object
dateCreated object
postalCode int64
lastSeen object
yearOfCreation int64
yearCrawled int64
monthOfCreation object
monthCrawled object
NoOfDaysOnline int64
NoOfHrsOnline int64
yearsOld int64
monthsOld int64
dtype: object
The only columns with a wrong data type are the dataCrawled, dateCreated and lastSeen, let's convert than to the date data type and set the dataCrawled columns as the DataFrame index.
# Change the data type
dataset.dateCrawled = pd.to_datetime(dataset.dateCrawled)
dataset.lastSeen = pd.to_datetime(dataset.lastSeen)
dataset.dateCreated = pd.to_datetime(dataset.dateCreated)
# Set the date as the DataFrame index
dataset.set_index('dateCrawled', inplace=True)
# Sort the DataFrame by the index
dataset.sort_index(inplace=True)
Now, let's see the start and end date of the crawl process, and how many days it took to finish:
print(f' Start date: {dataset.index[0]}')
print(f' End date: {dataset.index[-1]}')
print(f' Total days: {dataset.index[-1] - dataset.index[0]}')
Start date: 2016-03-05 14:06:22
End date: 2016-04-07 14:36:58
Total days: 33 days 00:30:36
Data Cleaning
Now, let's see if there is any missing value, duplicate values or any variable that need to be transformed.
# Checking missing values
dataset.isnull().any()
name False
seller False
offerType False
price False
abtest False
vehicleType False
yearOfRegistration False
gearbox False
powerPS False
model False
kilometer False
monthOfRegistration False
fuelType True
brand False
notRepairedDamage False
dateCreated False
postalCode False
lastSeen False
yearOfCreation False
yearCrawled False
monthOfCreation False
monthCrawled False
NoOfDaysOnline False
NoOfHrsOnline False
yearsOld False
monthsOld False
dtype: bool
The fuelType column has missing values, let's take a closer look and see how many.
dataset.fuelType.isnull().sum()
189
There is 189 missing values for fuelType column. As the fuelType will be important for the analysis, let's remove the rows with the missing data.
dataset = dataset[dataset.fuelType.notnull()]
Now let's see if there is any duplicate value in the dataset.
dataset.duplicated().sum()
25
There are 25 duplicated rows in the dataset, let's see some of then.
# print the first 10 duplicated rows
dataset[dataset.duplicated(keep=False)].head(10)
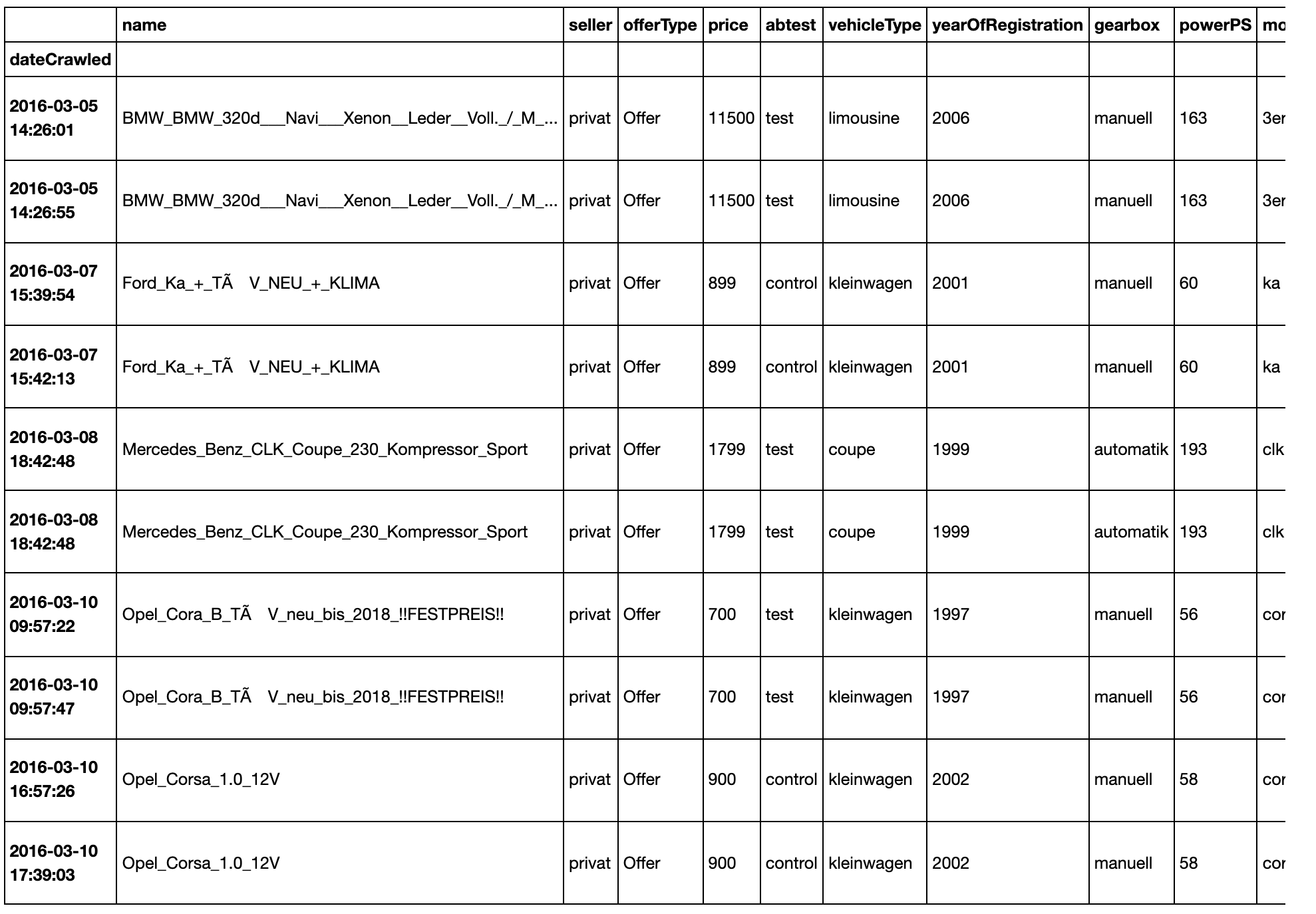
Now, let's remove the duplicated rows:
dataset.drop_duplicates(inplace=True)
print(f'Number of rows: {dataset.shape[0]}')
Number of rows: 313473
That it's for the data cleaning step. Now let's start the data analysis.
Questions
The data analyses will be driven by several questions.
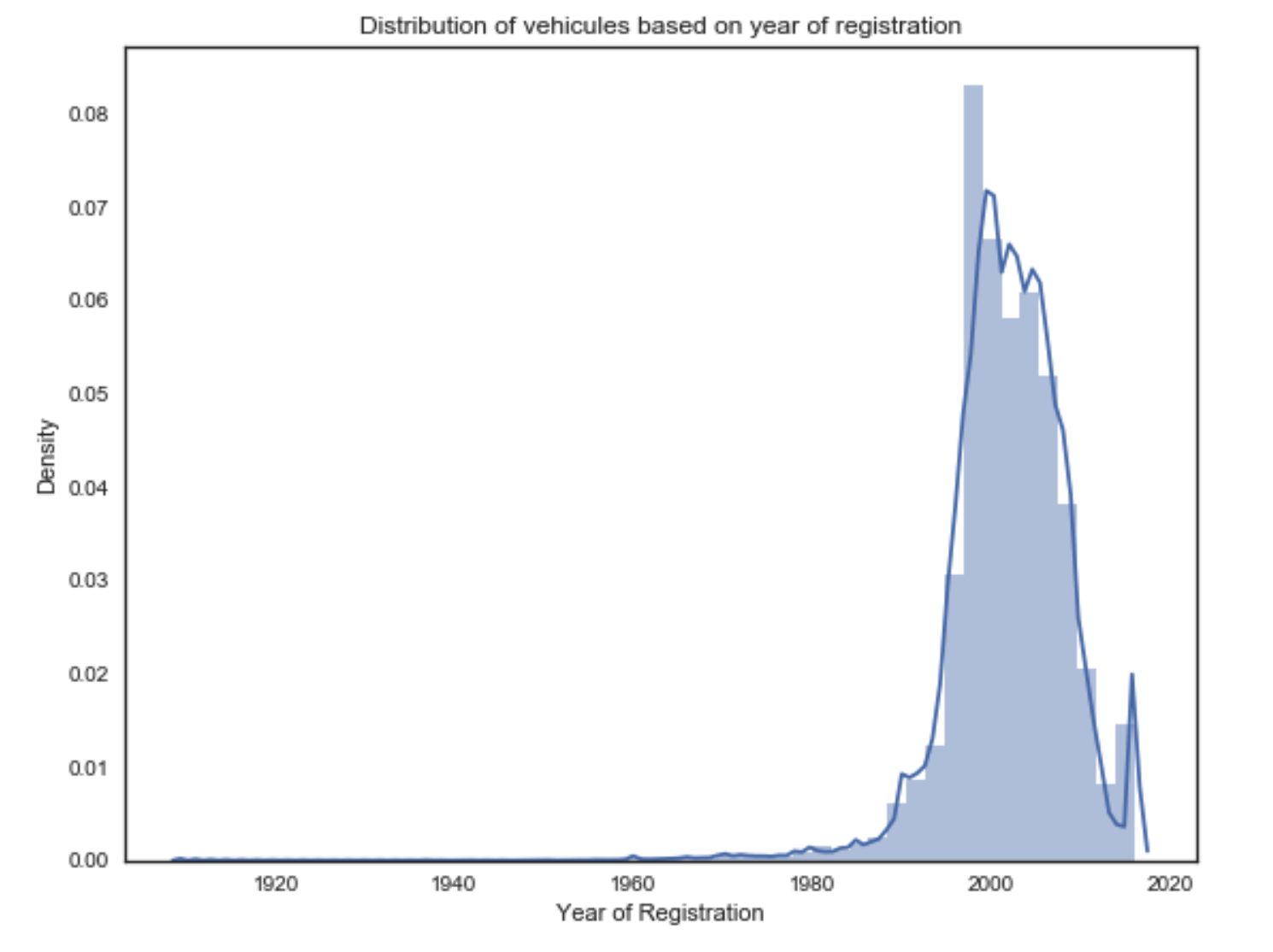
1) What is the distribution of vehicles by the year of registration?
# Creates a plot with the distribution of vehicules based on year of registration
fig, ax = plt.subplots(figsize=(9,7))
sns.distplot(dataset['yearOfRegistration'], ax=ax)
ax.set_title('Distribution of vehicules based on year of registration')
plt.ylabel('Density')
plt.xlabel('Year of Registration')
plt.show()
To complement the plot above we can see the frequency of car by years grouped in chunks of 5 years as presented in the table below:
bins = list(range(1900,2021,5))
out = pd.cut(dataset.yearOfRegistration, bins=bins)
counts = pd.value_counts(out).sort_index()
print('YEAR INTERVAL\tFREQUENCY')
print(counts)
YEAR INTERVAL FREQUENCY
(1900, 1905] 0
(1905, 1910] 98
(1910, 1915] 1
(1915, 1920] 1
(1920, 1925] 3
(1925, 1930] 10
(1930, 1935] 10
(1935, 1940] 17
(1940, 1945] 15
(1945, 1950] 20
(1950, 1955] 41
(1955, 1960] 233
(1960, 1965] 252
(1965, 1970] 650
(1970, 1975] 765
(1975, 1980] 1393
(1980, 1985] 2047
(1985, 1990] 6086
(1990, 1995] 23454
(1995, 2000] 90309
(2000, 2005] 99213
(2005, 2010] 67645
(2010, 2015] 13126
(2015, 2020] 8084
Name: yearOfRegistration, dtype: int64
From the plot and table above we can see that the majority of cars are from the years 1990 to 2010. An interesting fact, we have almost one hundred cars registered between 1905 and 1910.
2) What is the Variation of the price range by type of vehicle?
So, let's see the types of vehicles in the dataset:
print(dataset.vehicleType.unique())
['kleinwagen' 'kombi' 'cabrio' 'suv' 'limousine' 'Other' 'bus' 'coupe'
'andere']
For this analysis we will create a Boxplot that shows the variation and outliers (atypical value) of the data.
The figure below explain the information provided by a boxplot.
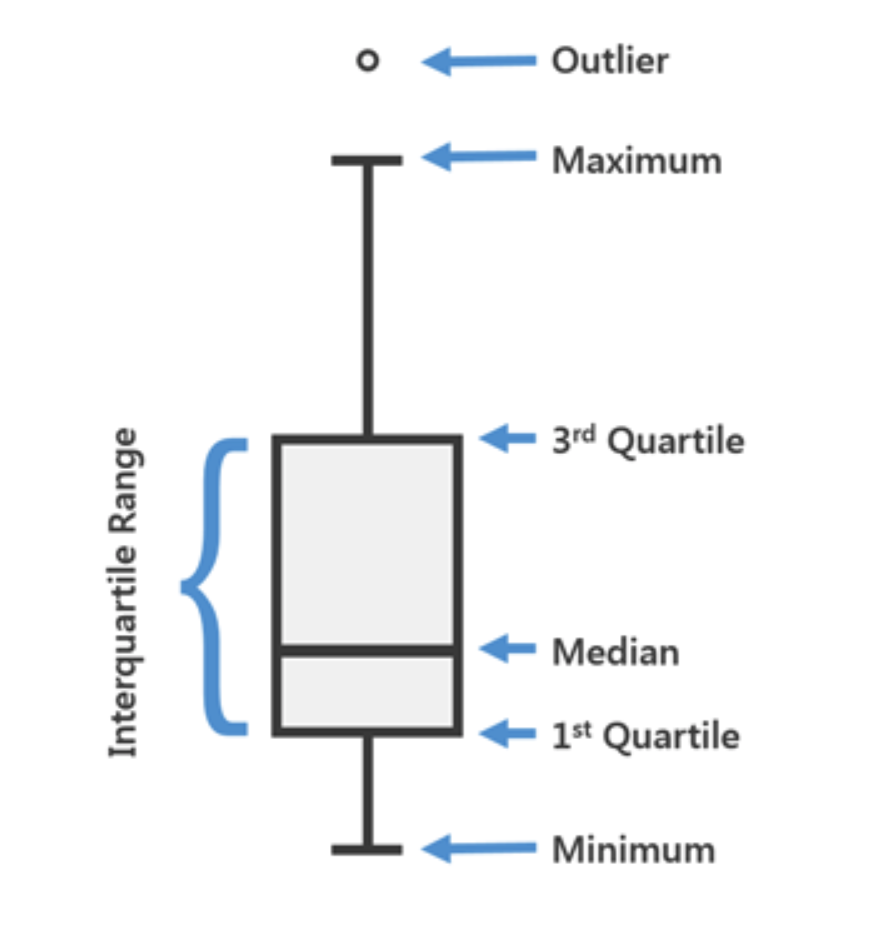
Once we understand the boxplot, we can see the boxplots for the price range for each type of vehicle.
fig, ax = plt.subplots(figsize=(12,8))
sns.boxplot(x='vehicleType', y='price', data=dataset)
ax.set_xlabel('VEHICLE TYPE')
ax.set_ylabel('PRICE')
plt.show()
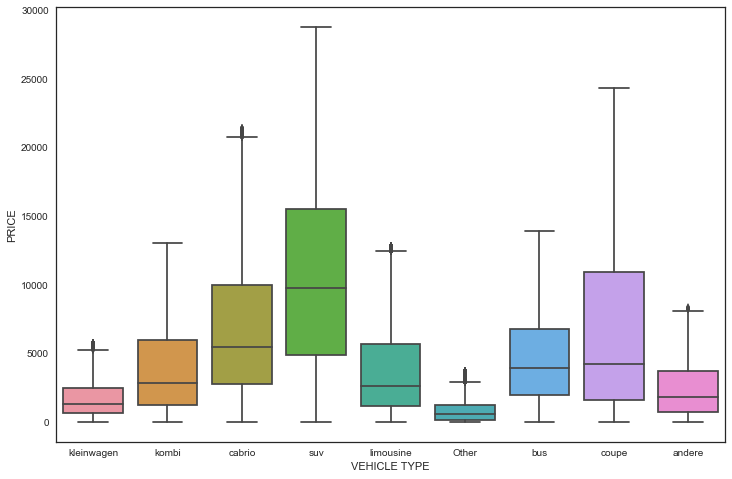
From the figure above, we can see, for example, that the median value of an SUV is 10,000, with most values between 5000 and 15000, and the maximum price is something close to 30,000.
Also, we can see that excluding the Other type, kleinwagen and andere are the types of vehicles with the lowest price range.
3) What is the number of vehicles for selling by type of vehicle?
# Create a count plot that shows the number of vehicles belonging to each category
g = sns.factorplot(x='vehicleType', data=dataset, kind='count', size=6, aspect=1.5, palette="BuPu")
g.set_xlabels('VEHICLE TYPE')
g.set_ylabels('COUNT')
g.ax.set_title('Number of vehicles belonging to each category')
# to get the counts on the top heads of the bar
for p in g.ax.patches:
g.ax.annotate((p.get_height()), (p.get_x()+0.1, p.get_height()+500))
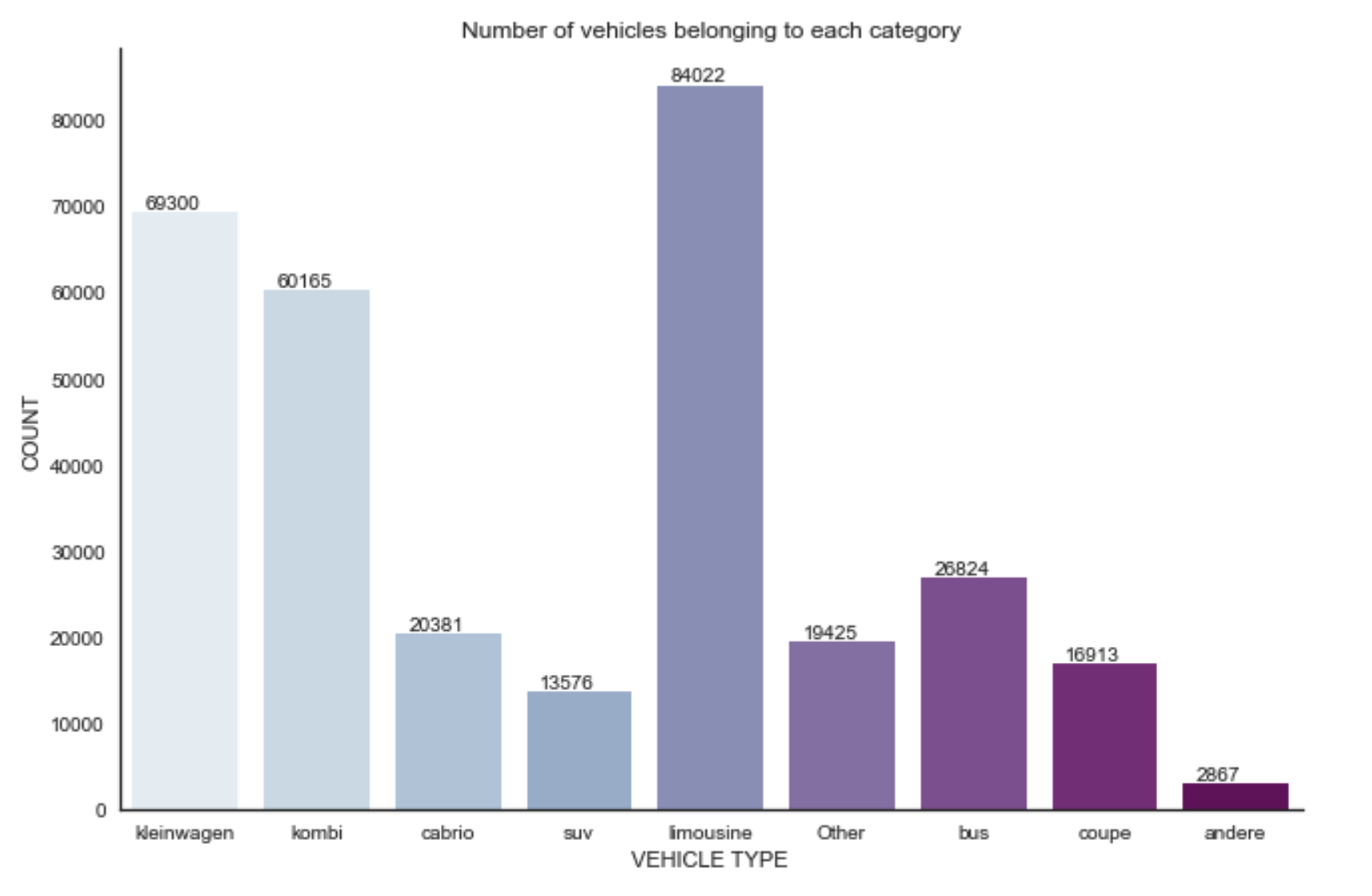
From the figure above we see that the limousine is the top type of car for selling, and the andere has the least amount of cars for sale.
4) How many vehicles belong to each brand?
# Create a plot that shows the number of vehicles for each brand
sns.set_style('whitegrid')
g = sns.factorplot(y="brand", data=dataset, kind="count", palette='Reds_r', size=8, aspect=1.5)
g.ax.set_title('Number of vehicles for each brand')
g.ax.xaxis.set_label_text("NUMBER OF VEHICLES", fontdict={'size':18})
g.ax.yaxis.set_label_text("BRAND", fontdict={'size':18})
plt.show()
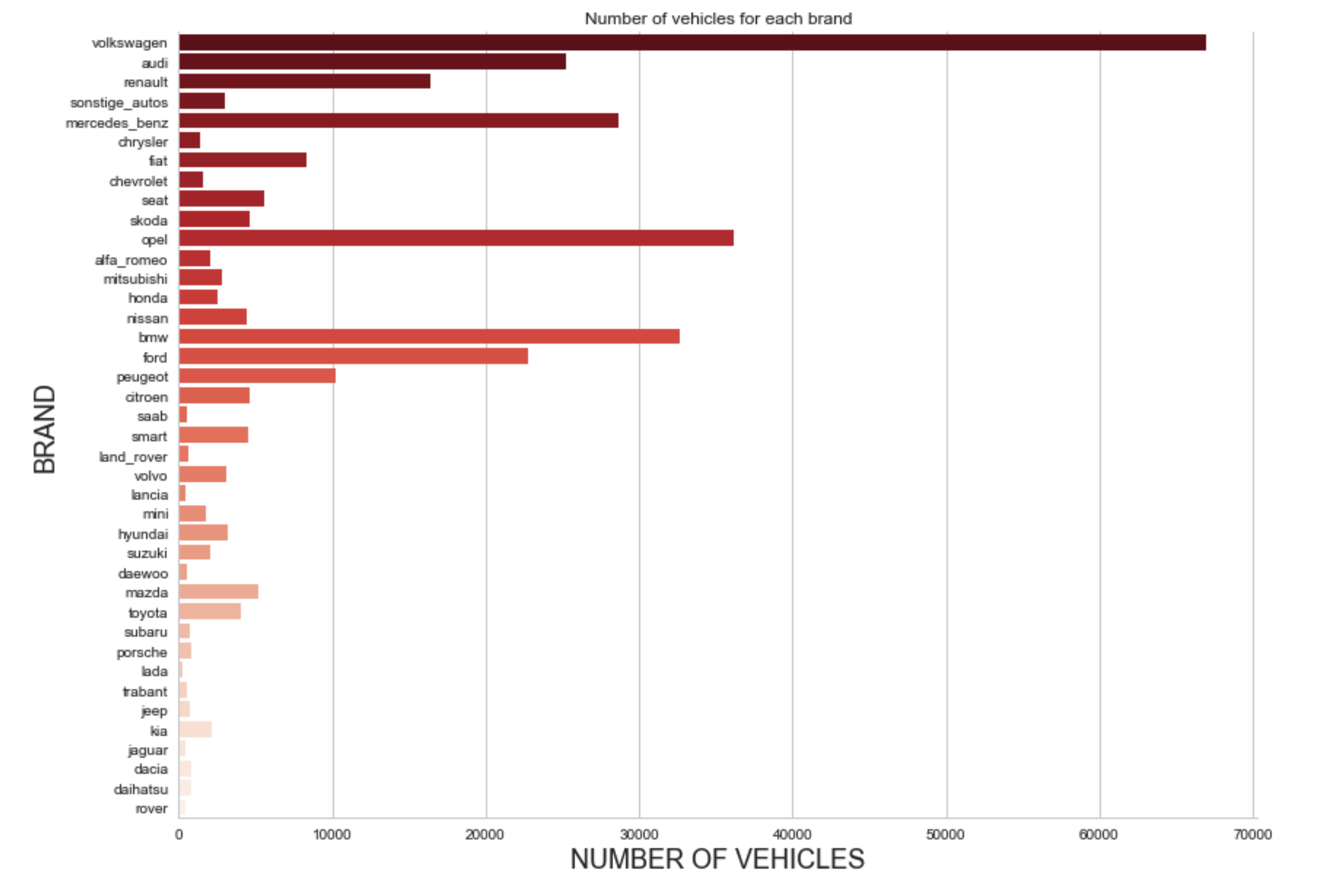
From the plot, we see that Volkswagen has the majority of cars for selling.
5) What are the average vehicle price based on the type of vehicle and the type of gearbox?
fig, ax = plt.subplots(figsize=(10,6))
sns.barplot(x='vehicleType', y='price', hue='gearbox', data=dataset)
ax.set_title("Mean price of vehicles by brand and gearbox")
ax.set_xlabel("VEHICLE TYPE")
ax.set_ylabel("MEAN PRICE")
plt.show()
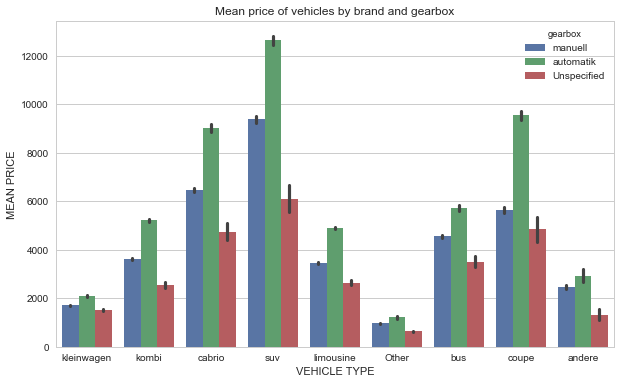
From the plot, we see that automatic SUV has the higher mean price.
6) What is the average vehicle price based on the type of fuel and the type of gearbox?
fig, ax = plt.subplots(figsize=(10,6))
sns.barplot(x='fuelType', y='price', hue='gearbox', palette='husl', data=dataset)
ax.set_title("Mean price of vehicles by fuel and gearbox types")
ax.set_xlabel("FUEL TYPE")
ax.set_ylabel("MEAN PRICE")
plt.show()
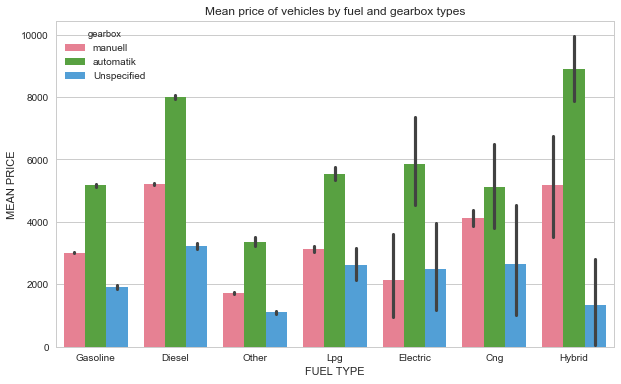
From the plot, we see that hybrids and automatic cars have the higher mean price.
7) What is the average power of a vehicle by type of vehicle and type of gearbox?
fig, ax = plt.subplots(figsize=(10,6))
sns.barplot(x='vehicleType', y='powerPS', hue='gearbox', palette='husl', data=dataset)
ax.set_title("Mean power of vehicles by type and gearbox")
ax.set_xlabel("VEHICLE TYPE")
ax.set_ylabel("MEAN POWER")
plt.show()
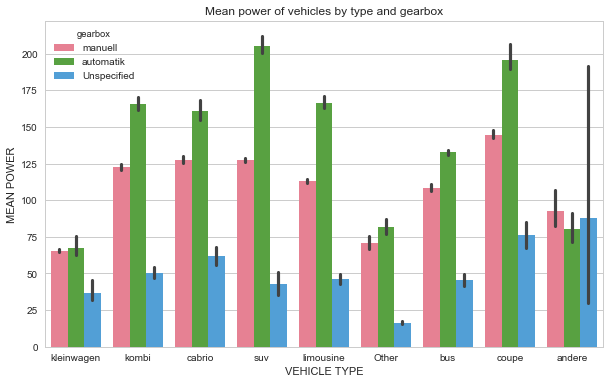
From the plot, we see that automatic SUVs cars have the higher mean power.
8) What is the average price of a vehicle by brand and type of vehicle?
To answer this question, let's use a heat map, that is a graphical representation of data where the individual values contained in a matrix are represented as colors.
# Computes the mean average price per brand and type
trial = pd.DataFrame()
for b in list(dataset["brand"].unique()):
for v in list(dataset["vehicleType"].unique()):
z = dataset[(dataset["brand"] == b) & (dataset["vehicleType"] == v)]["price"].mean()
trial = trial.append(pd.DataFrame({'brand':b , 'vehicleType':v , 'avgPrice':z}, index=[0]))
trial = trial.reset_index()
del trial["index"]
trial["avgPrice"].fillna(0,inplace=True)
trial["avgPrice"].isnull().value_counts()
trial["avgPrice"] = trial["avgPrice"].astype(int)
# Create a Heatmap with Average price of one vehicle per brand, as well as type of vehicle
tri = trial.pivot("brand","vehicleType", "avgPrice")
fig, ax = plt.subplots(figsize=(15,20))
sns.heatmap(tri,linewidths=1,cmap="YlGnBu",annot=True, ax=ax, fmt="d")
ax.set_title("Heatmap - Average price of one vehicle per brand and type of vehicle",fontdict={'size':20})
ax.xaxis.set_label_text("VEHICLE TYPE",fontdict= {'size':20})
ax.yaxis.set_label_text("BRAND",fontdict= {'size':20})
plt.show()
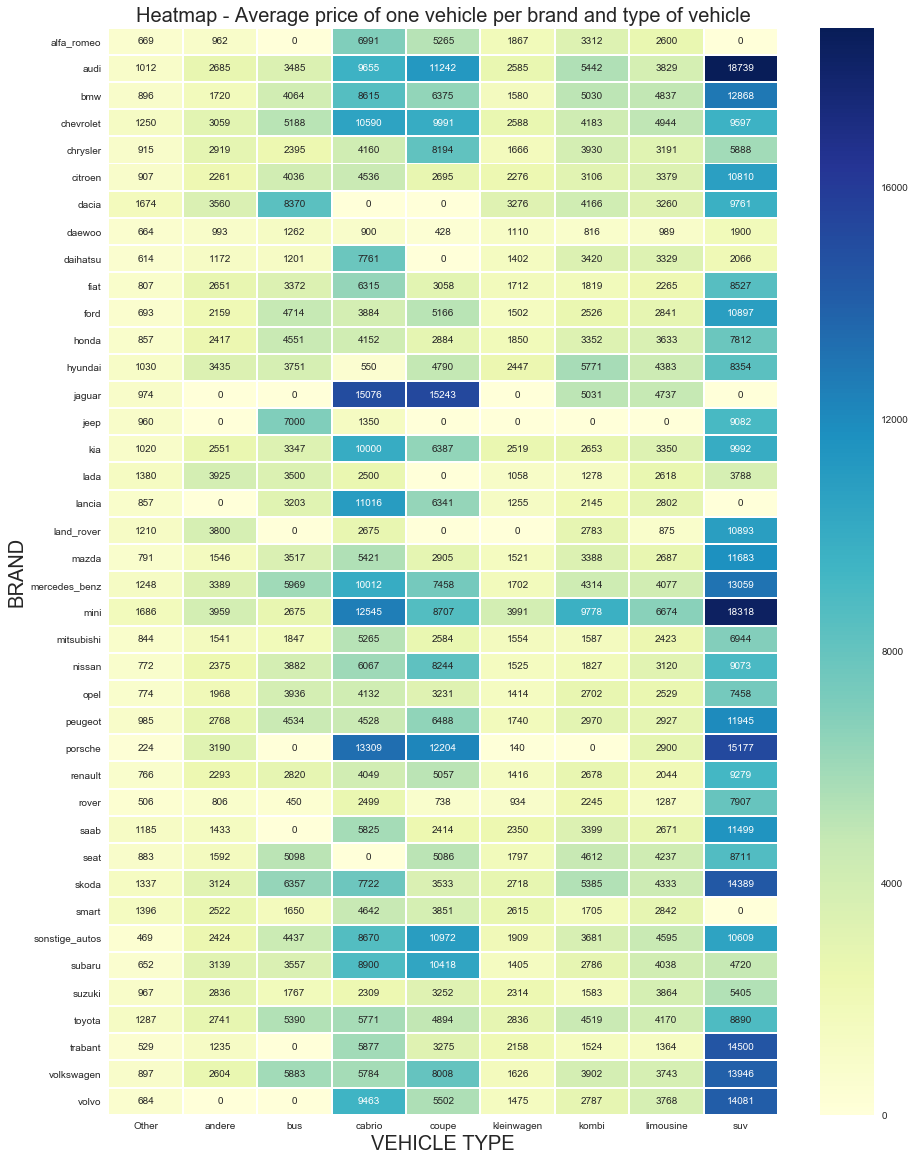
From the heat map above we see that SUV by Audi has the higher average price.
Final Remarks
This project presented a exploratory data analysis of a database of used cars scraped from eBay Kleinanzeigen.
A data cleaning process was peformed and several questions were answers through advanced visualizations.