Accelerating claim approval by an insurance company
This project aimed to build a predictive model that can predict the probability that a particular claim will be approved immediately.

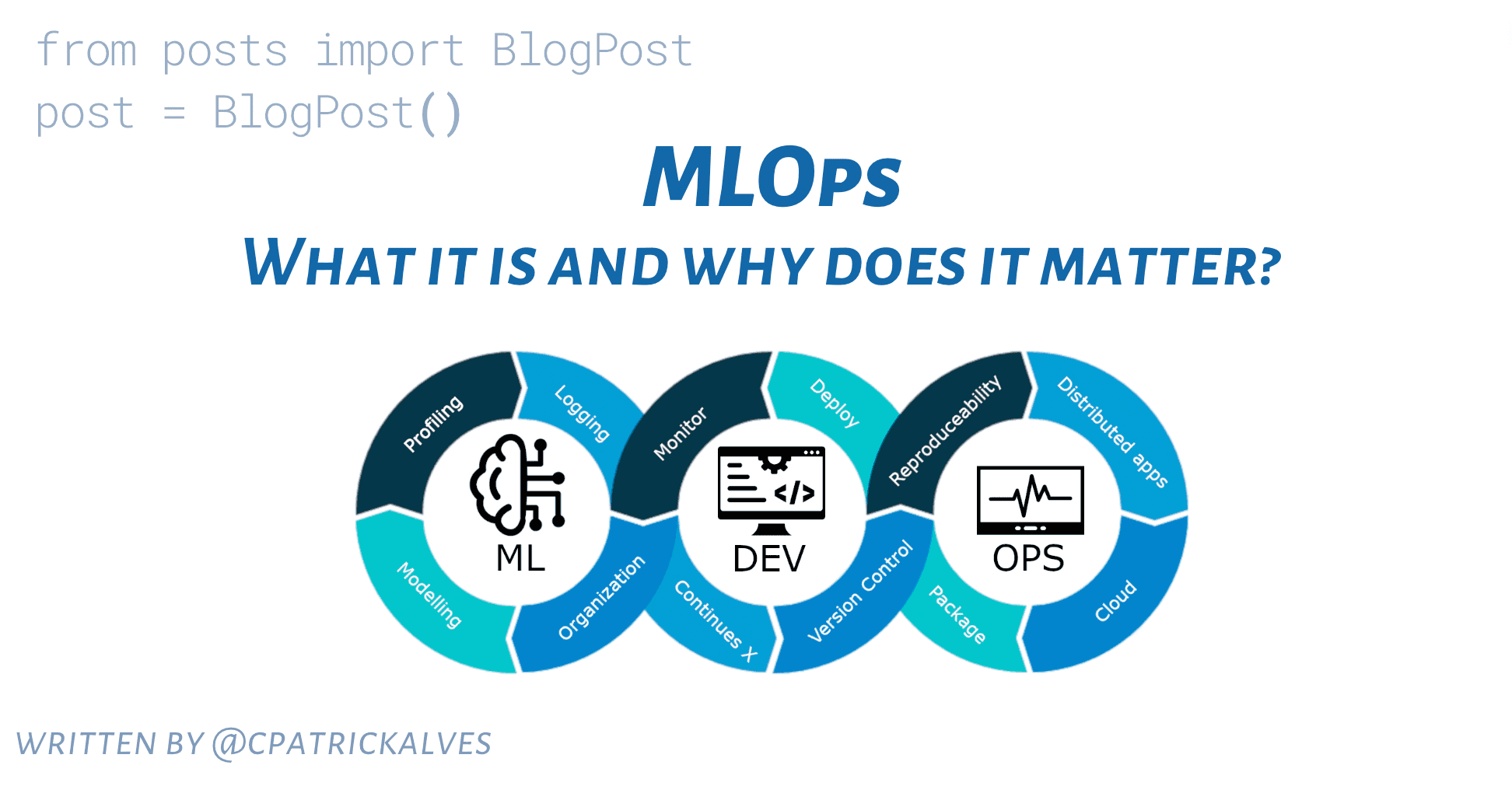
I help companies to leverage Machine Learning to create innovative products through an end-to-end machine learning development process that designs, builds, and manages reproducible, testable, scalable, and evolvable ML-powered software with minimal cost.
This project is the result of a Kaggle competition promoted by Data Science Academy in December of 2019.
The aim of this competition is to build a predictive model that can predict the probability that a particular claim will be approved immediately or not by the insurance company based on the resources available at the beginning of the process, helping the insurance company to accelerate the payment release process and thus provide better service to the client.
Competition page: https://www.kaggle.com/c/competicao-dsa-machine-learning-dec-2019
Problem
Claims should be carefully evaluated by the insurer, which may take time. Even simple claims need to be review by someone. This costs time and money for the insurance company.
Task
Build a predictive model that can predict the probability that a particular claim will be approved immediately or not based on patterns found in historical and anonymous data.
Solution
My goal is not to predict whether a new order should be approved immediately, but to predict the probability of immediate approval of each claim. This allows the insurer to prioritize orders over 80% likely to be approved immediately, for example.
I've used Python to perform an Exploratory Data Analysis (EDA) using visual and quantitative methods to understand and summarize a dataset without making any assumptions about its contents. Then I've performed Data Cleaning and built several Machine Learning models to compute the probability that a particular claim will be approved immediately.
Results
The evaluation metric for this competition is Log Loss (the smaller the better).
In this competition my best score was 0.4929 and I got position 38 on the competition leaderboard.
This result means that the solution can help insurance companies identify claims that can be accepted immediately based on available resources at the beginning of the process. This will speed up the payment clearance process and thus provide better customer service.
Source code
The solution is also available at Github.
I've written a blog post with details about the solution.